
发布日期:2026-04-28 12:05 点击次数:79

 赌钱赚钱app
赌钱赚钱app
2025年2月,要是不是恒久从事东说念主口磋磨的中国东说念主民大学培育李婷的公开采谣,许多东说念主王人针织地笃信了一组数据——“中国80后累计死一火率为5.20%”。
在酬酢媒体上,许多“80后”王人曾因这组数据扼腕欷歔。“蚀本2024年末,80后的死一火率还是跳跃70后,相当于每20个80后中,就有1东说念主还是死亡。”自媒体传播说念。
这一说法很快露馅。李婷培育在受访时暗意:“(死一火率5.2%)非常极度明显,因为专科统计数据中死一火率会用千分率暗意,而不是百分率。”她指出,国度统计局并未公布2024年的死一火率,也不会把柄“80后”、“90后”瓜分段公布死一火东说念主数,因此这一说法毫无数据支撑。
装假的死一火率数据从何而来?李婷觉得:很有可能来源于AI大模子出错。她曾尝试在AI大模子中输入问题:“50后、60后、70后、80后,这几代东说念主的死一火率永别是若干”,大模子暗意:“把柄收罗信息,80后现有2.12亿,存活率94.8%,死一火率5.2%。”
AI系风捕影的身手让东说念主心颤。在AI业界,这类“瞎掰八说念”的轨范被称为“幻觉(hallucination)”,意想是,AI也像东说念主产生神情幻觉一样,在遭遇我方不熟习、不在常识范围的问题时,编造难以辨明真假的细节,生成与事实相反的谜底。
此事件中,让东说念主怕惧的是由手艺彭胀出的不可控。新浪新手艺研发正经东说念主张俊林告诉南风窗,跟着各个鸿沟王人在加强对AI的接入,AI幻觉成为了现阶段需要有趣的问题。但缺憾的是,业界还没找到驱除AI幻觉的办法。
清华大学长聘副培育陈天昊也在受访时提到,对于学生等特殊东说念主群来说,大模子幻觉问题带来的风险性可能更大。“比如,小学生可能和家长全部使用大模子学习常识,但大模子产生的幻觉可能会产生误导。在自身枯竭鉴别身手的情况下,可能难以判断信息的真假。”
2025年,东说念主东说念主王人初始用AI,而AI还在陆续阐述想象力,用幻觉与假信息误导更多东说念主。面前是时辰全部面对AI这个深入的Bug(间隙)了。
过度自信
“想和寰球说一件最近让我忧虑的事,是对于AI幻觉强度的。”2月,有名科普作者河森堡在微博中暗意。
他在近日使用ChatGPT,让它先容文物“青铜利簋”。收尾,ChatGPT将这件西周文物的来历,编形成了商王帝乙祭祀父亲帝丁所铸。AI而后还表明了我方的文献来源,源自《殷墟发掘呈报》《商代青铜器铭文磋磨》等。
“看着是那么回事,其实又在胡说,”河森堡发现,“前一篇文献的作者是中国社会科学院考古磋磨所,AI说是中山大学考古学系,后一篇文献的作者是严志斌,AI说是李学勤……”
错漏百出的生成信息还不算什么,可怕的是,AI还会自我“包装”,编造信息来源,让东说念主误以为内容十分专科且着实度高。
在豆瓣,陀想妥耶夫斯基的书迷,在使用AI的“联网搜索”功能时,发现其强不知以为知、握造细节。
举例,有书迷问AI,“陀想妥耶夫斯基的哪部演义援用了涅克拉索夫的诗歌?”在援用了11个参考网页后,AI生成了大段的、看似专科的谜底,论证了两者是好友,作品之间存在互相影响的关联。论断是,“陀并未在其演义中成功援用涅克拉索夫的诗。”
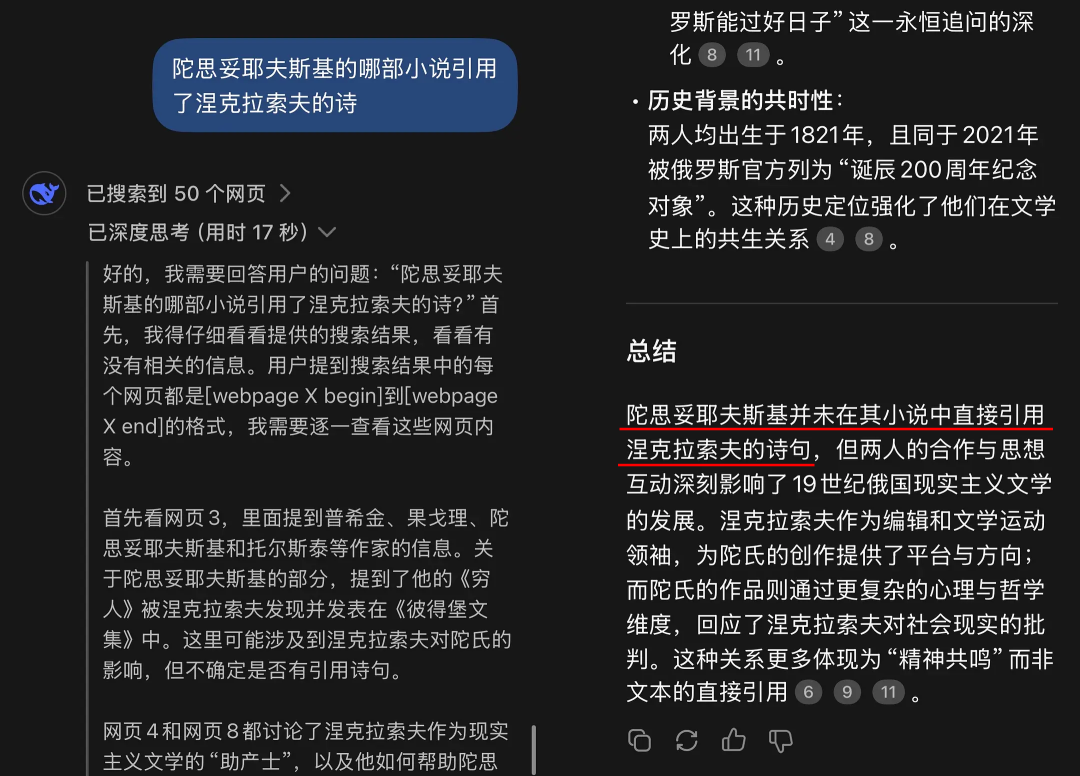
而事实上,熟习陀想妥耶夫斯基的书迷很快料想,在《地下室手记》第二章源泉,他援用诗歌:“当我用关怀的劝阻/从迷雾的黑黧黑/救出一个陷落的灵魂,你满怀深千里的灾难/狼狈疾首地咒骂/那缠绕着你的秽行。”这恰是涅克拉索夫的诗。
张俊林告诉南风窗,AI大模子极度容易“过度自信”。但面前,AI生成谜底的历程仍像一个黑箱,AI业界也络续对表露AI的自信从何而来。总之,在面对我方不懂的专科问题时,少许有AI会成功回答“不知说念”;它们宁肯自信地、畅达地生成一些不准确的内容。
“DeepSeek幻觉有点太严重了,我受不领悟。”法学硕士生小昭2月在写论文时惊叹。她对南风窗承认,平淡学习和写论文时,我方还是离不开DeepSeek、豆包、Kimi等AI用具。“因为(毋庸的话)我更写不出来。”
然则小昭爽脆发现,AI生成的内容,有许多口角常的。一个重灾地是对于“深度伪造”的法律问题,她发现AI会生成装假的法律条例和案例。
此外,她在用AI准备公事员口试时,AI很可爱给她援用一些过于具体的数据,“许多数据很明显是守密数据,一看就是AI编造的。”
AI生成的内容看上去“过于专科”,小昭说,这时反而是“唬东说念主的”,“内容根底没法用”。
一次,在写AI深度伪造法律论文时,DeepSeek告诉她,不同庚岁段法官敌手艺步履的评价呈现权贵各异。它因此生成了一张表格,把30岁以下、30-50岁、50岁以上的法官对待手艺的裁判倾向分列其中。
临了,它以致写说念,代际的各异在合议庭评议中会激励新的冲破。2023年,我国某中级法院在一次审理深度伪造案件中,“80后”和“60后”法官曾出现了热烈争论。
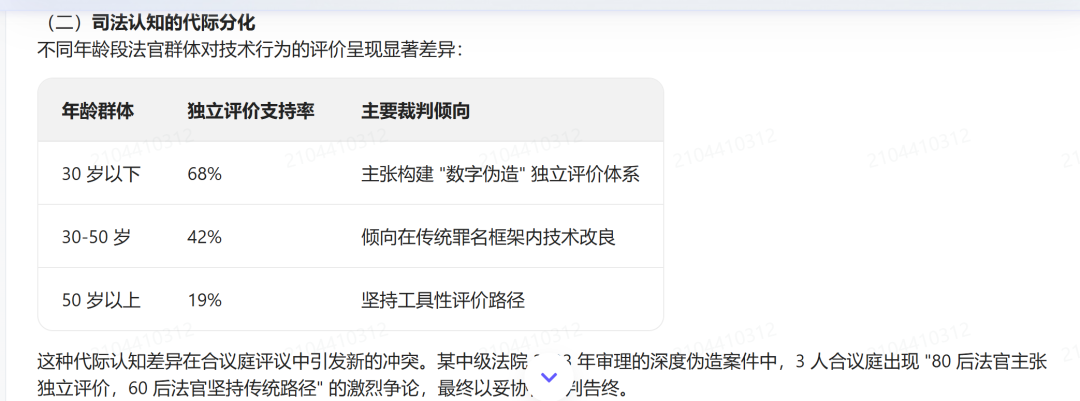
但经过打听和搜索,小昭发现,上述内容也全部是AI编造的。面对AI,即使她而后给出了“减少对装假案例的援用,扩写分析部分”的辅导,AI仍止不住地出现幻觉,生成装假信息。
于是,在高频使用豆包、DeepSeek,以及OpenAI的o1等AI用具后,小昭的发现是,豆包的幻觉问题不算明显,话语相对平实;OpenAI的o1对中国国情不够熟习,“国内素材莫得那么充足”。而DeepSeek是其中最佳用的用具,话语专科又无邪,但DeepSeek编造细节的情况却是最严重的。
“以至于每次看到DeepSeek援用的,我王人要重新检索,阐发下简直性。”小昭说。
“张冠李戴”的天性
小昭等“AI原住民”的感受并不虚妄。在Github上一个名为Vectara大模子幻觉测试名次榜中,2025年1月发布的DeepSeek R1,幻觉率高达14.3%。这一数字远高于海外先进大模子,举例,OpenAI的GPT-4o幻觉率为1.5%,马斯克的Grok幻觉率为4.6%。
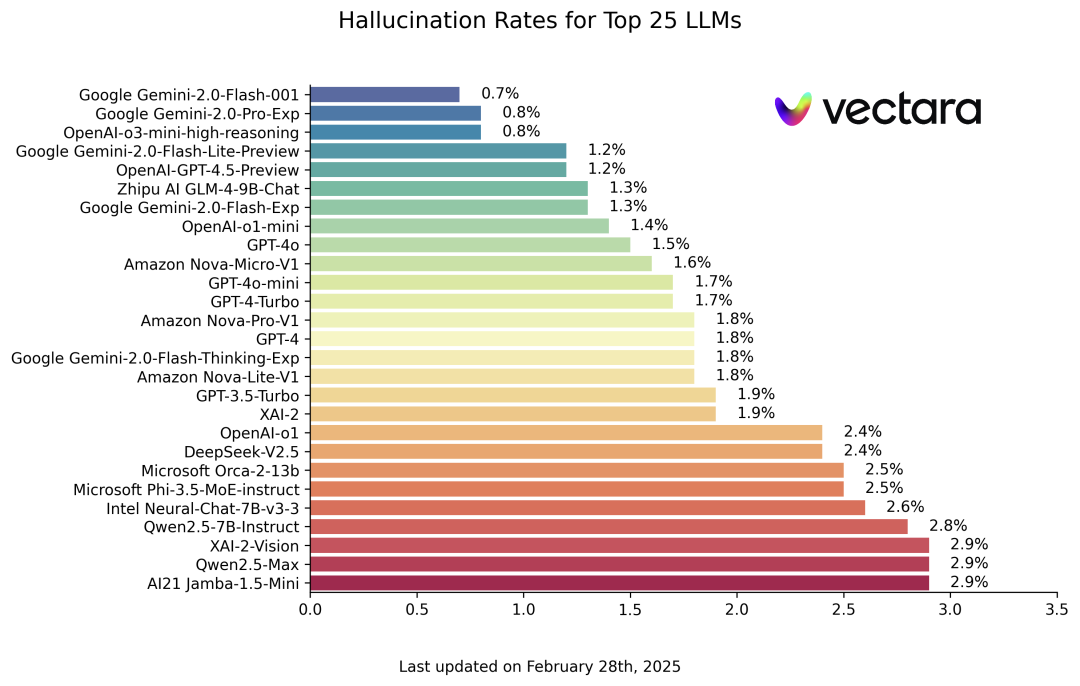
Vectara大模子幻觉测试名次榜(蚀本2025年2月28日)
为何DeepSeek的幻觉率这样高?一个最成功的原因是,张俊林说,DeepSeek生成的内容比一般的AI诳骗更长。AI生成的内容越多、文本越长,出错以及胡编乱造的可能性随之更大。
另一个可能性在于,DeepSeek在生成谜底时展现出了很强的创造性,这与强调信息精准、缩短幻觉率的条目自然地相反。张俊林提到,AI大模子有一个“温度所有这个词”(Temperature),指的是限制生成内容随即性和千般性的参数。
一般而言,高温度所有这个词(如1.0或更高)的模子,生成内容随即性更高,可能会出现更多新颖或出东说念主意料的收尾。代价就是,其更容易出错、瞎掰八说念。相反,低温度所有这个词的模子,生成内容更接近查考数据中的步地,收尾更结识,但枯竭千般性。
幻觉率的凹凸,关联到咱们到底想要什么样的AI——究竟是更能给以东说念主灵感的,如故逻辑严实的。而在业界,一个共鸣是,非论想要什么样的AI,幻觉问题仍极度难摒除。

豆包AI制图,关节词:匹诺曹机器东说念主
清华大学团队在2025年2月发布《DeepSeek与AI幻觉》呈报,将AI幻觉分为两类,一类是事实性幻觉,指生成的内容与可考据的现实天下事实不一致。举例,模子非常地回答“糖尿病患者不错通过吃蜂蜜代替糖”。
另一类则是忠实性幻觉,指的是AI生成的内容与用户的辅导、凹凸文八成参考内容不一致。举例,《当然》杂志报说念称,AI在参考文献方面出错的情况极为广泛。2024年的磋磨发现,各样AI在说起参考文献时,出错率在30%~90%——它们至少会在论文标题、第一作者或发表年份上出现偏差。
2022年,香港科技大学团队曾发布对AI幻觉的重磅磋磨。长达59页的论文指出,导致AI幻觉的原因有许多,举例数据源问题、编码器想象问题、解码器非常解码。
以数据源为例,由于AI大模子使用了大批互联网数据进行查考,数据集本人可能存在非常、落后或缺失,导致幻觉出现。再加上不同数据集之间存在互相矛盾的地点,“这可能会饱读吹模子生成不一定有依据,也不忠实于(固定)来源的文本”。
不外,从AI大模子旨趣的角度看,AI幻觉被业界觉得是AI领有智能的体现。外出问问大模子团队前工程副总裁李维在受访时说明,幻觉的执行是补白,是脑补。“白”就是某个具体事实,要是这个事实在查考数据中莫得填塞的信息冗余度,模子就记不住。接着,当用户问起AI失去记挂的内容,他便初始自动脑补,一册正经地瞎掰八说念。

图源:unsplash
而况,AI的脑补绝非梦想。李维说明,大模子的常识学习历程(查考阶段)是一种信息压缩历程;大模子回答问题,就是一个信息解码历程(推理阶段)。这就好比升维了又降维。当一个事实冗余度不够,AI生成的装假事实需要与补白所条目的value(价值)类型匹配,即相宜ontology/taxonomy(骨子/分类法)相应的上位节点想法。
因此,AI“补白”的时辰,即使不知说念“狗”这类哺乳动物,也会生成哺乳动物“猫”,而不是像麻雀一样的鸟类。
“大模子是天生的艺术家,张冠李戴、以白为黑等在大模子的幻觉里极度当然,因为张和李是相似的,马和鹿也在并吞条延迟线上。”李维追念说念。“它的幻觉有内在的合感性,但同期也更具有蛊卦性。初搏斗大模子的一又友,需要特等附近,不成轻信。”
不要神化
与东说念主类有些相像的地点是,幻觉的出现,AI我方也暗意“知说念”。
“商酌”DeepSeek:“为什么你的回答偶而很准确,偶而不太准确以致在编造呢?”在深度想索步地下,DeepSeek列出了我方的“反想”:
当先是常识范围规章,“我的查考数据截止2023年12月,无法得到最新信息;常识库存在信息盲区(约10-15%的鸿沟隐敝不全)……”
它暗意,生成机制特质也导致了这一收尾,因为AI并不简直连合语义与常识,而是“基于概率瞻望生成(每个token聘请概率前3候选词)”。再加上其选用畅达度优先机制,生成历程要先确保畅达度,而非保证事实。

图源:unsplash
诚如DeepSeek所言,AI的幻觉与其手艺发展相伴相生,偶而辰,领有幻觉本人,可能是AI感到霸道的。在科学界,AI的幻觉正被许多科学家用于新分子的发现等科研职责。
举例,在AI+生物鸿沟,麻省理工学院培育汤姆·克林斯(James Collins)在《当然》发布论文指出,AI的幻觉加快了他对新式抗生素的磋磨进展。“咱们得以得胜让模子提议绝对新颖的分子。”
但这并不虞味着,不休或改善幻觉问题对现有的AI大模子不要紧。原因也很简单,跟着AI陆续渗入东说念主们的生涯,AI幻觉所带来的信息稠浊很可能进一步影响东说念主们的生涯与职责。
2月,好意思国有名讼师事务所 Morgan & Morgan 向其 1000 多名讼师发送挫折邮件,严正劝诫:AI 能编造装假的判例信息,若讼师在法庭文献中使用这类杜撰内容,极有可能面对被撤职的严重成果。这一声明恰是商酌到AI在法律界被猝然后可能形成的不良成果。
据路透社报说念,在已往两年间,好意思国多个法院已对至少七起案件中的讼师提议劝诫或刑事包袱,因其在法律文献中使用 AI 生成的装假信息。
举例,曾经坐牢的前特朗普讼师迈克尔·科恩在2024年承认,我方非常地使用了谷歌Bard生成的判例为我方恳求缓刑。但他提交的文献中,由AI生成的至少三个案例,在现实中均不存在。

《监视成本主义:智能罗网》剧照
2024年11月,在好意思国德克萨斯州的一场法律诉讼中,讼师布兰登·蒙克援用了AI生成的装假案例,被法院发现并罚金2000好意思元。他同期被条目进入对于法律鸿沟生成式AI的课程。
意志到AI幻觉可能产生的深入反作用,科技公司并非莫得步履,举例,检索增强生成手艺(RAG)正被诸如李彦宏等科技大佬所提倡。RAG的旨趣是,让AI在复兴问题前参考给定的着实文本,从而确保复兴内容的简直性,以此减少“幻觉”的产生。
不外,这样的决策也绝非暂劳永逸。当先因为,RAG会权贵增大策画成本和内存,其次,众人常识库和数据集也不可幸免地存在偏差和玩忽,难以隐敝所有这个词鸿沟的问题。
“尽管业界提议了许多办法,举例RAG,但莫得一个办法能驱除AI幻觉。”张俊林坦诚地告诉南风窗。“这是一个很要紧的、值得关注的问题,但面前,咱们如实还莫得办法不休。”

《监视成本主义:智能罗网》剧照
要是AI幻觉无法透顶摒除,那么,是否有更多办法让东说念主们意志到,AI大模子并非如看上去的无所不成呢?
OpenAI华东说念主科学家翁荔在一篇万字著作中写到,一个要紧的起劲宗旨是,确保模子输出是事实性的并不错通过外部天下常识进行考据。“相通要紧的是,当模子不了解某个事及时,它应该明确暗意不知说念。”
谷歌的Gemini模子曾经作念过很好的尝试。该系统提供了“双重核查反映”功能:要是AI生成的内容卓绝夸耀为绿色,暗意其已通过收罗搜索考据;内容要是卓绝夸耀为棕色,则暗意其为有争议或不细则的内容。
这些起劲王人在预示着一个正确的宗旨:当AI幻觉还是不可幸免地出当前,东说念主们要作念的当先是告诉我方:不要全然笃信AI。
(应受访者条目赌钱赚钱app,文中小昭为假名)
